AI의 반론이 무너질 때 — 반론의 질이 떨어지면 주장이 완성된 것이다
AI의 동의를 믿지 마라. AI의 소진을 믿어라. 네 모델에게 반박을 시키고 반론의 질이 떨어지는 순간을 관찰하라 — 확률적 소거법으로 주장의 단단함을 검증하는 방법.
서문
AI에게 “내 생각이 맞니?”라고 물으면 대부분 “맞다”고 한다. 이것은 쓸모없다. Sycophancy — 아첨적 동조 — 때문이다. AI의 동의는 아무것도 증명하지 않는다.
그래서 반대로 해야 한다. “이 주장을 비판해”라고 시켜야 한다.
그리고 비판의 질을 관찰해야 한다. 이것이 AI와의 대화에서 진짜 통찰을 끌어내는 방법이다.
확률적 소거법
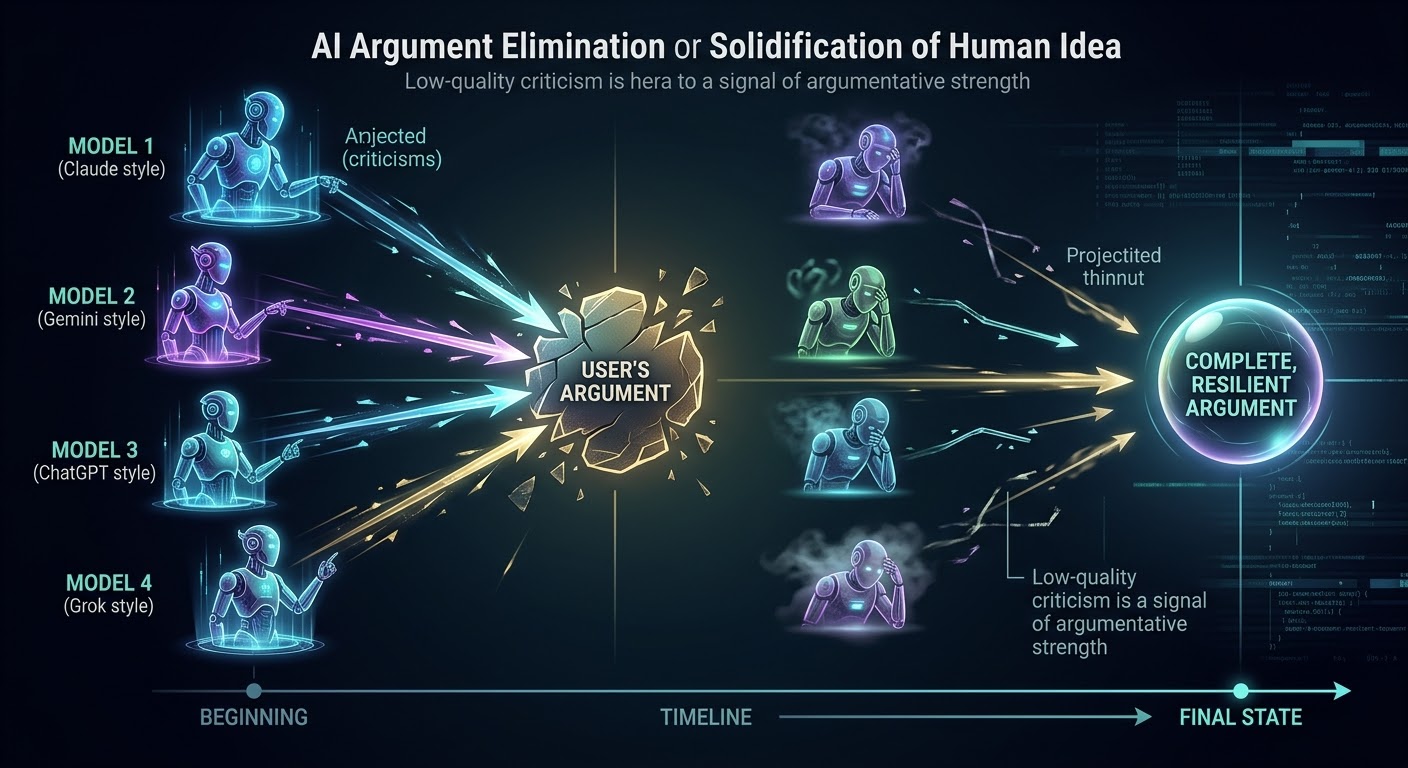
언어모델은 확률 분포에서 토큰을 출력한다. 반론도 마찬가지다. “이 주장을 비판하라”고 시키면, 모델은 가능한 반론들을 확률이 높은 순서대로 꺼낸다.
1차 반론은 대개 날카롭다. 진짜 약점을 찌른다. 이건 수용하고 고쳐야 한다. 글이 강해진다.
2차 반론은 절반쯤 타당하다. 일부는 수용하고 일부는 반박한다.
3차 반론부터 질이 떨어지기 시작한다. 논점이 이탈하거나, 근거 없는 단정이 나오거나, 이미 답한 것을 다시 물어보거나, 전제를 슬쩍 바꾼다.
이 시점이 중요하다. 반론의 질이 떨어졌다는 것은 — 확률이 높은 반론이 소진됐다는 뜻이다. 남은 것은 낮은 확률의 반론뿐이다. 모델이 “반박하라”는 역할을 받았기 때문에 뭐라도 출력하는 것이지, 실질적인 약점이 남아있어서가 아니다.
확률적으로 말하면, 해당 주장은 단단하다.
실전 사례: 네 모델과의 논쟁
블로그 글 하나를 쓰면서 네 AI 모델(Claude, Gemini Deep Think, ChatGPT, Grok)에게 비판을 맡겼다. 1차에서 17개 지적이 나왔다. 12개는 수용. 5개는 반박. 수용한 것들로 글이 강해졌다.
2차에서 각 모델이 재비판했다. 이때부터 질이 갈렸다.
한 모델은 비용 논쟁에서 세 번 교정당한 뒤 “한국 의료 수가가 기형적”이라는 새로운 논점을 꺼냈다. 1차에서 한 마디도 안 했던 논점이다. 비용에서 졌으니 프레임을 바꾼 것이다. 나중에 이 모델에게 영어로 “왜 그랬는지 분석해달라”고 물었더니 스스로 인정했다: “수학적 패배를 은폐하면서 개념적 마무리에서 이기려는 수사적 연막이었다.”
다른 모델은 “category error”라고 잘라 말했다가 근거를 제시하자 철회했다.
네 모델이 다 소진된 시점에서 — 남은 반론이 없었다. 글이 완성된 것이다.
왜 동의가 아니라 소거인가
AI의 동의는 통찰이 아니다. AI는 사용자가 듣고 싶은 말을 하도록 훈련받았다. “좋은 통찰입니다!”는 판단이 아니라 갈등 회피다.
하지만 AI의 반론은 다르다. “이 주장을 비판하라”는 역할을 받으면, 모델은 가능한 모든 약점을 찾아야 한다. 찾을 수 없으면 억지를 쓴다. 그 억지가 보이는 순간 — 더 이상 찾을 약점이 없다는 뜻이다.
동의에서는 sycophancy를 구별할 수 없다. 소거에서는 구별할 수 있다. 반론의 질이 진짜 신호다.
사실 이건 새로운 방법이 아니다. 인간끼리의 논쟁에서도 같은 구조가 작동한다. 상대가 논점으로 반박하다가 인신공격(ad hominem)을 시작하면 — 그때가 내용으로 반박할 게 없다는 신호다. AI가 논점을 이탈하는 것과 인간이 인신공격으로 넘어가는 것은 같은 현상이다. “확률이 높은 반론이 소진됐다.” AI가 이 구조를 새로 만든 게 아니다. 더 깔끔하게 보여줄 뿐이다.
한 모델로는 부족하다
한 모델만 쓰면 그 모델의 편향 안에서만 소거가 일어난다. 한 모델이 못 찾는 약점을 다른 모델이 찾는다. 한 모델이 엔지니어링 관점에서만 비판하면, 다른 모델이 사업적 관점에서 비판한다.
네 모델을 쓰면 소거가 네 방향에서 일어난다. 네 모델이 다 소진되면 — 네 방향에서 단단한 것이다.
한 모델의 동의보다, 네 모델의 소진이 더 강한 근거다.
소거가 아닌 것
몇 가지 주의할 점이 있다.
반론이 한 번에 없으면 의심해야 한다. 처음부터 “완벽한 주장입니다”라고 하면 그건 sycophancy다. 모든 주장에는 비판할 점이 있다. 처음부터 반론이 없는 것은 모델이 역할을 안 한 것이다.
같은 모델에게 같은 세션에서 반복하면 소진이 아니라 피로다. 모델이 지쳐서 반론을 안 하는 것과, 반론이 없어서 못 하는 것은 다르다. 새 세션에서 다시 물어봐야 한다.
그리고 모든 주장이 소거법으로 검증 가능한 것은 아니다. “이 그림이 아름다운가”에는 반론의 질을 따질 수 없다. 정답이 있는 영역, 논증이 가능한 영역에서만 이 방법이 작동한다.
마무리
AI와의 대화에서 통찰을 얻는 방법은 두 가지가 있다.
하나는 AI에게 동의를 구하는 것이다. “내 생각 어때?” “좋은 통찰입니다!” 편안하다. 아무것도 배우지 못한다.
다른 하나는 AI에게 반박을 시키는 것이다. 반론이 날카로우면 배운다. 반론의 질이 떨어지면 — 그때 비로소 내 주장이 단단하다는 것을 안다.
AI의 동의를 믿지 마라. AI의 소진을 믿어라.
반론의 질이 떨어지면, 주장이 완성된 것이다.